#0
user1
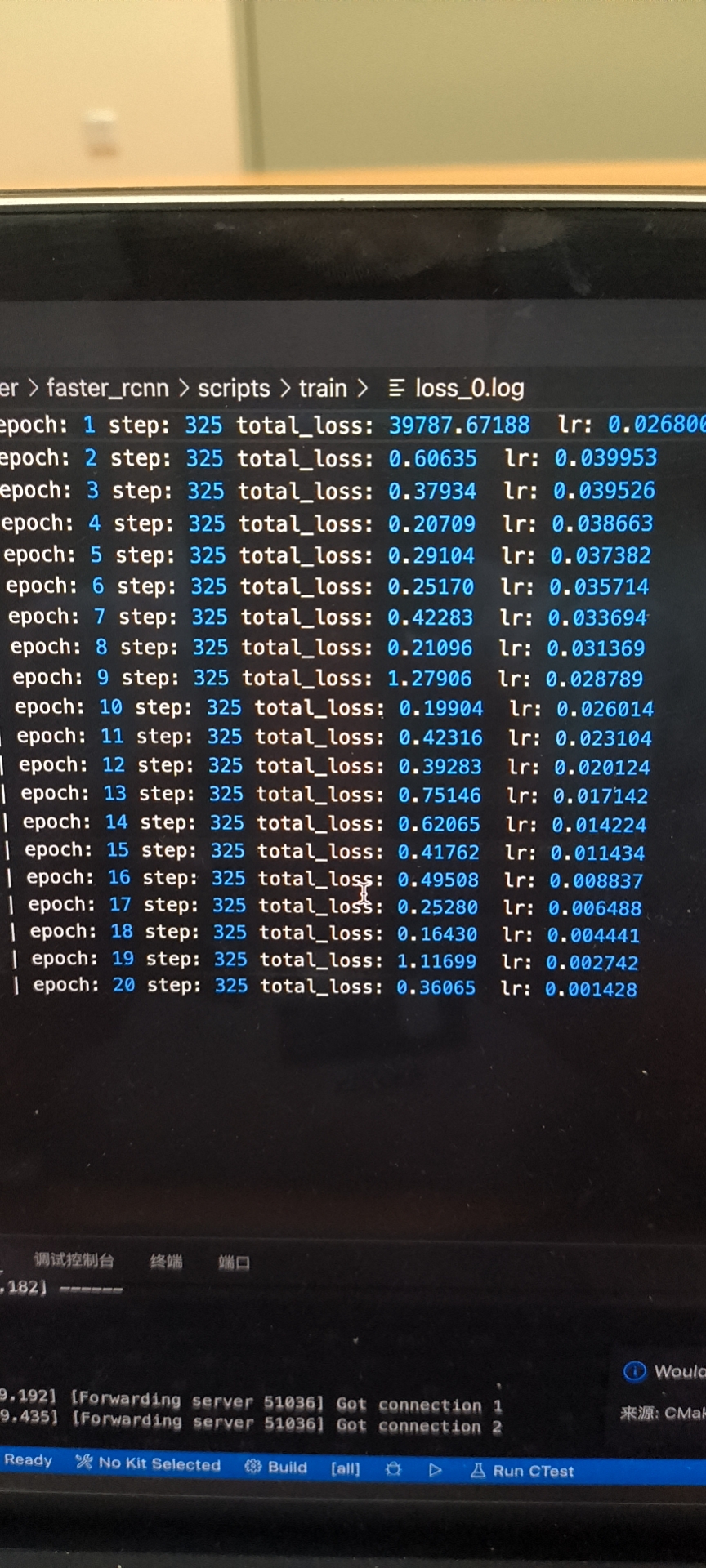
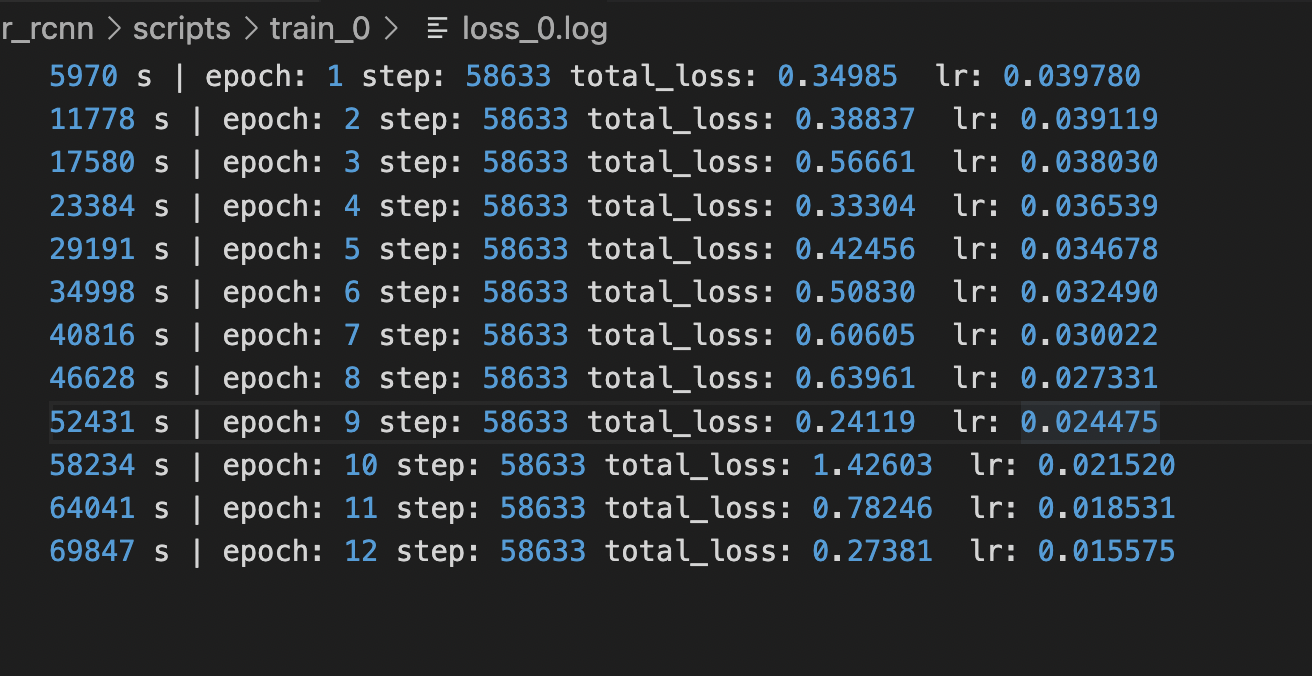
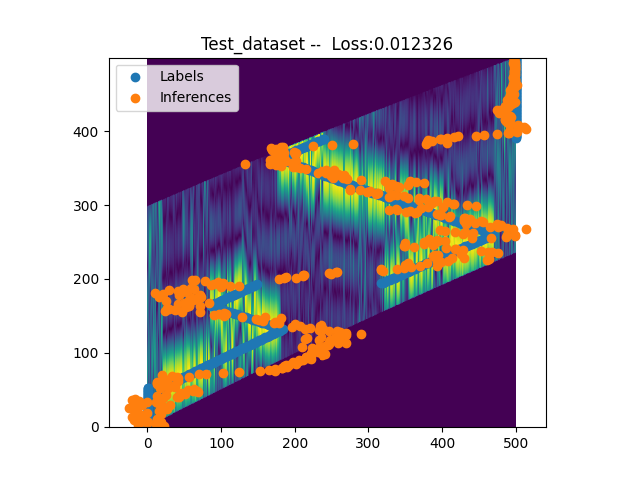
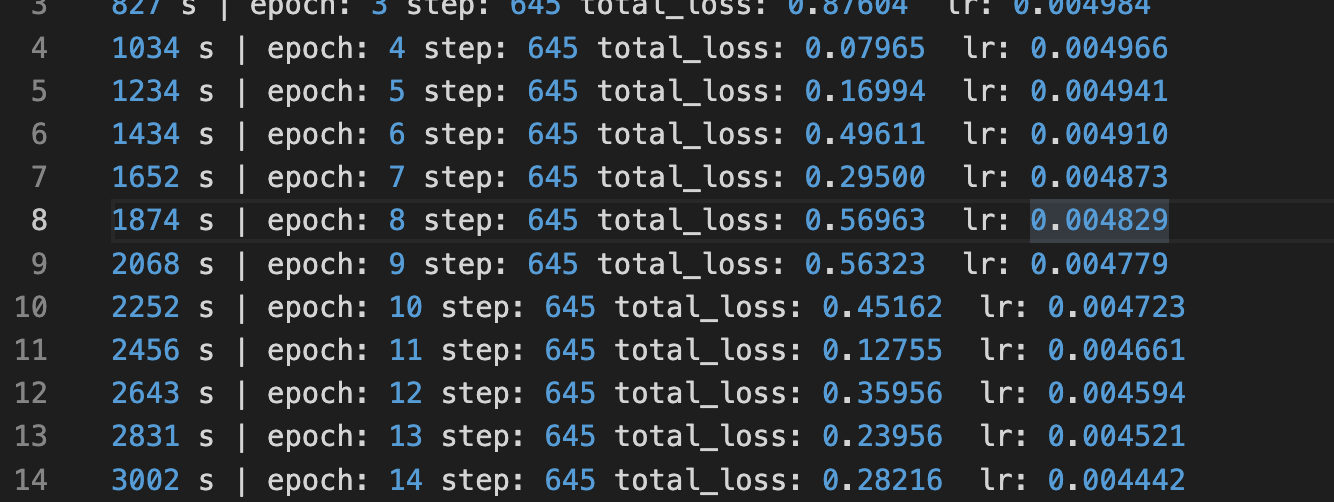
你看下里面学习率策略,8,11的时候会有大幅度下降。后面学习率应该就很低了。
#4
user1
你backbone的预训练权重用的是我里面生成的好的吧?带1.3的那个标志的。
#6
user1
那就没啥问题,可能就是需要调调参数。
#7
user2
我看了下代码。里面根本没用8 11那个参数。。
#8
user1
你再对一下vision和这个在学习策略代码上的差异。
#10
user1
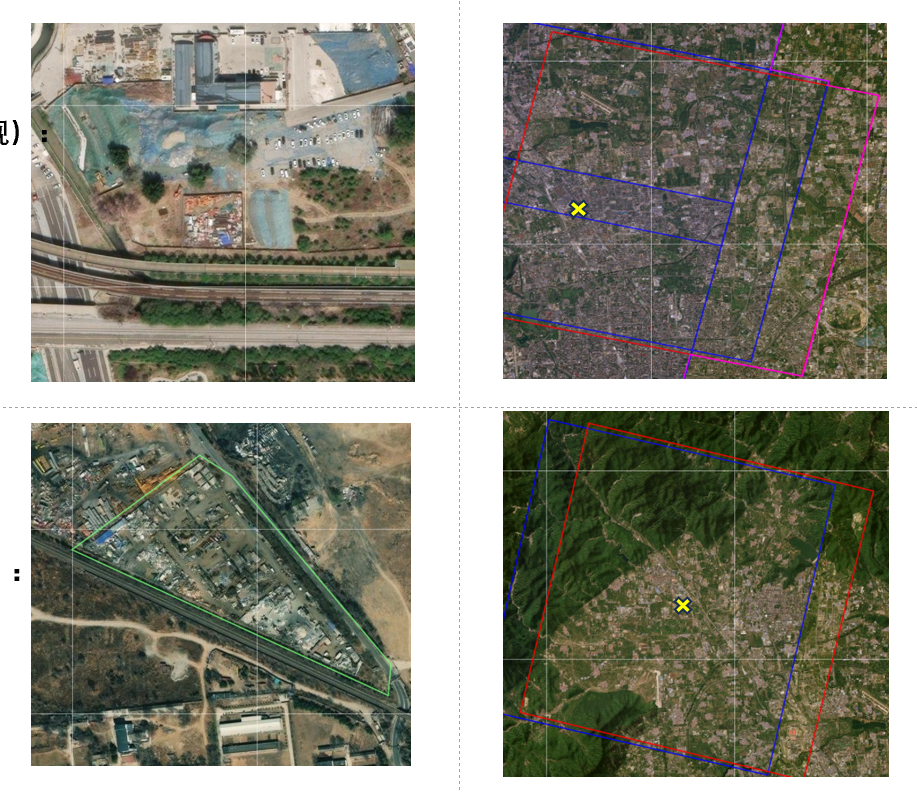
后面可以实验直接使用coco的那个faster rcnn权重加载进去训练dota数据集,做几组实验看看。你的数据集样本有多少?尺寸是多大呢?
#11
user2
就是咱们第一次测试的时候您发的那个权重是吧。
#15
user1
尺寸这个比较重要,是和coco数据有比较大的差异的地方。图片样本也很少。
#16
user2
对 coco单卡一个epoch得一个半小时。
#17
user1
那确实需要使用coco数据集的faster-rcnn的权重来训练了。
#19
user1
主要是你的数据量小了很多。coco数据集应该有19万的样本吧。不对,9万多好像。我也记不清了。
#20
user2
但是这个数据。它目标不见得会少。有40多万个目标。It contains 403,318 instances in total。
#21
user1
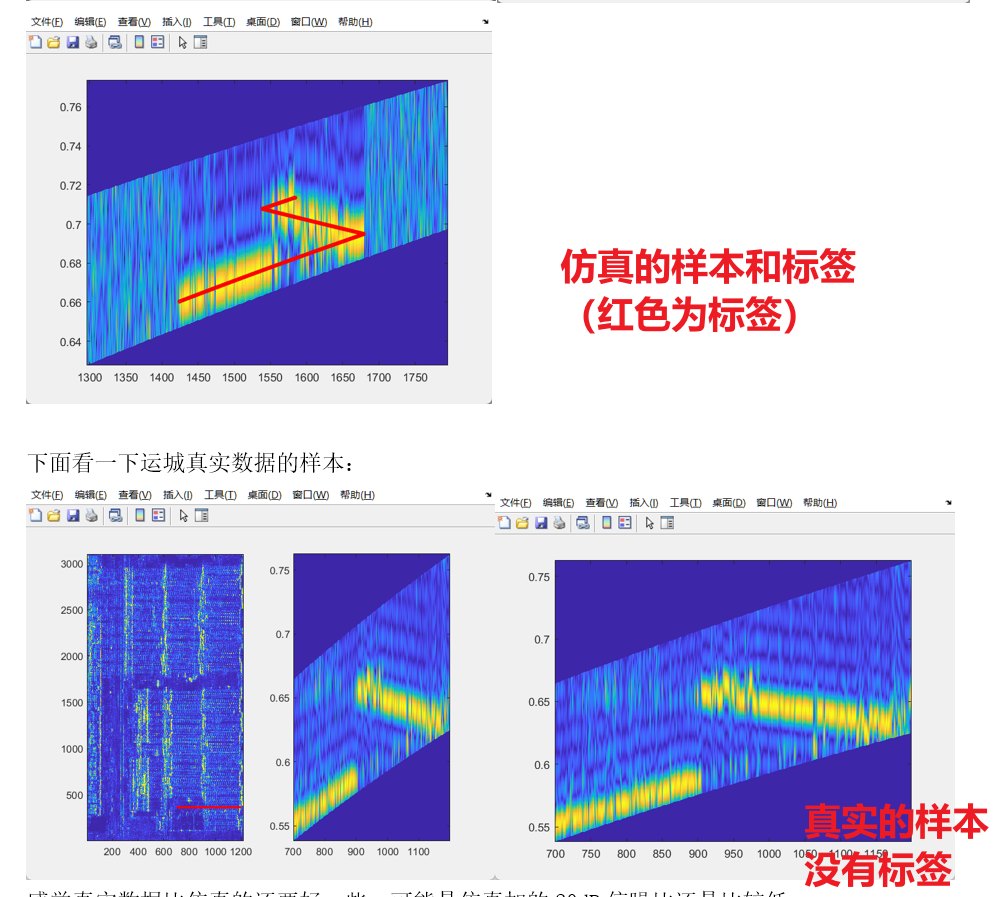
目标不少,但样本的辨识度太低了,学习难度就比较高。
#23
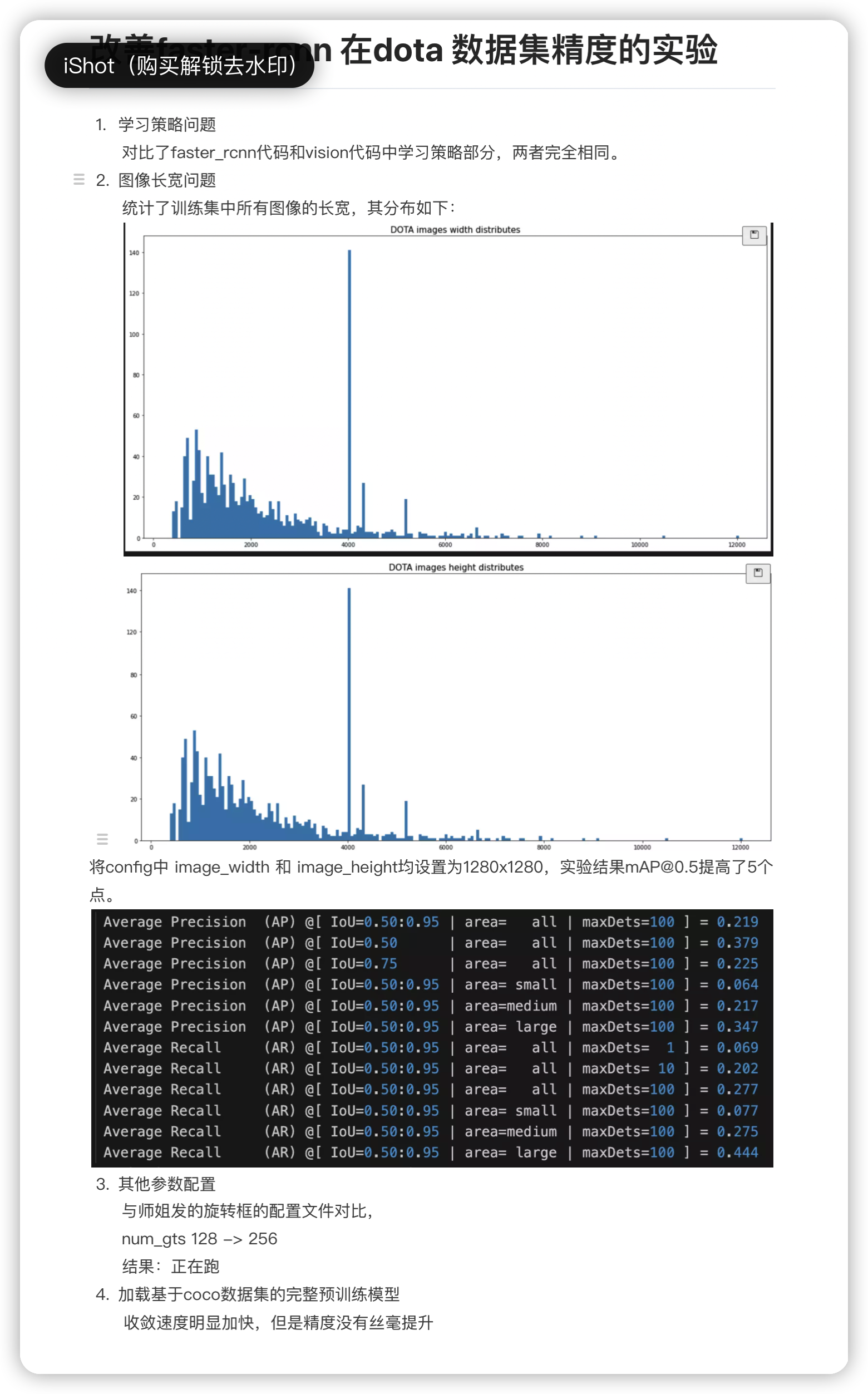
user1
里面有20000尺寸的,最好统计一下各个尺寸范围的比例,分析一下数据,设置一个比较好的resize 尺寸。
#25
user1
也可以参考参考之前开源代码里对dota数据集的超参设置。应该有不少人调过这个数据集。
#31
user1
,不慌,我们这才是实验性的跑起来,后面优化的地方还多。
#32
user2
老师 那个旋转框是不是先不着急加。
#35
user1
旋转框那个可以下个月上,这个月主要要把vit和swin的有效果出来。
#36
user2
嗯嗯 那我最近就先着重优化这个框架。
#41
user2
老师 和您汇报下目前的情况。换swin的同学说刚开始跑的时候也是没有输出,然后改了改参数有了一点点精度。
#43
user1
不过现在差距还是有些大,这样吧,裸训的话把轮数加大,训24epoch看下精度。
#45
user1
之前你实验室那个打榜数据要相关的参数介绍没呢?
#46
user2
打榜的那个没要到,王老师给了一个旋转框的。是基于metection框架的。然后image scale设的是512*512。其他的就有一个numgts不一样 我正在实验呢。
#48
user2
王老师就帮忙找到一个旋转框的。发现上升好慢 又给调回来了。因为基本上都是。50来个epoch才到最高的结果。
#49
user1
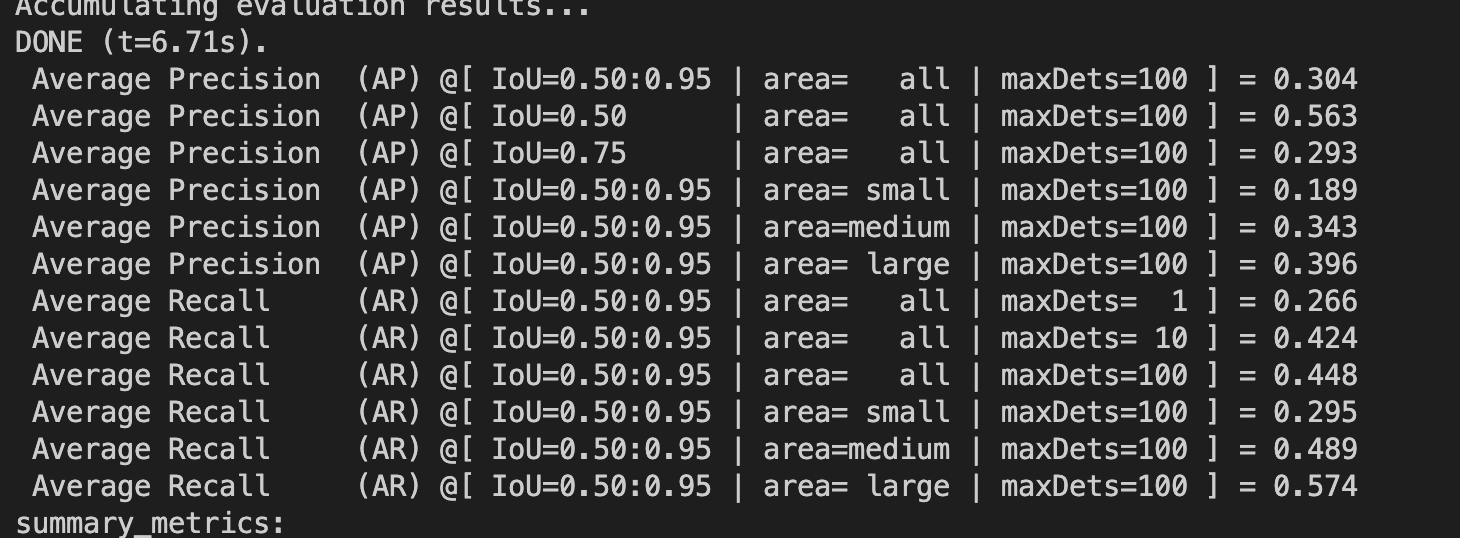
主要是要确定一下faster-rcnn模型对这个数据集的性能目前最高能做到什么地步,算法本身肯定也存在瓶颈。
#50
user2
我在博客里倒是找到一个。他的mAP@0.5也是30多。。不过博客可能参考性没那么大。
#51
user1
王老师发给你的旋转框配置是基于faster rcnn吗?
#53
user1
他的baseline map是多少呢?
#54
user2
她就发了一个配置文件。然后说这个精度差的有点多。
#56
user2
我问她精度多少她给忽略了。大概60可能差不多?我看了一下dota的论文。
#57
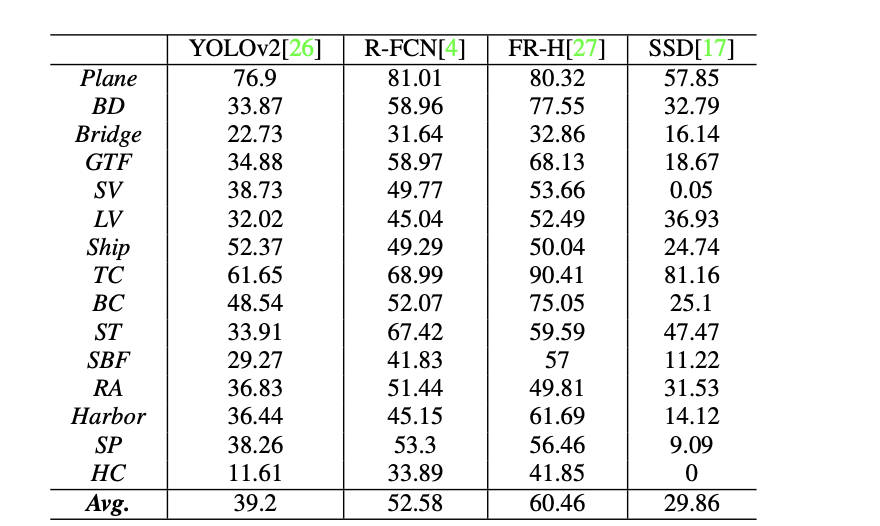
user1
我觉得70应该差不多,毕竟sota都79了。
#58
user2
没有没有。论文上也用faster rcnn 测了。这个模型是当时最高的。也就60。
#59
user1
那差一半啊,参数配置论文上有说吗?
#61
user2
咱现在38,他是60。emmm给了个代码。他说是基于这个代码改的。https://github.com/msracver/Deformable-ConvNets。
#62
user1
backbone用的应该不是resnet50。
#64
user1
-H?hrnet?那我们也用101跑一个看看。
#65
user2
他还用了一个小技巧。就是说这个图不是太大吗。然后就全都裁成1024*1024的。检测完了之后。再把结果拼起来。合在原图里。
#69
user1
大图变小图来检测,可以提高小目标的检测性能,应该是不太好拼接,比较麻烦。
#71
user1
那我们暂时目标调到接近60就行了。换res101来训练。
#73
user1
101的实现你参考vision里面的,直接拿过来应该可以用。
#75
user1
swin那个他之前找过我,它有加载swin的权重进去没呢?还是说直接裸训的。
#78
user1
那看来swin网络挺稳定的,速度咋样呢?
#79
user2
速度不知道,我问问。8分钟一个epoch。
#80
user1
嗯嗯,让他实验一下加载swin权重(方便后面使用mae预训练的)和 finetune的优化器和学习策略尝试一下mae里面配置的,transformer网络里通常都是用adamweightdecay优化器和cosine学习策略。胡雷毅那边反馈说swin网络跑起来太慢了,你们数据量应该也是比较小的。
#81
user2
嗯嗯 这个相当小了相比coco。我说错了老师 这个图的结果,他说是加载了预训练模型的。。
#82
user1
后面swin网络性能上还需要进一步优化一下。,我说呢,我记得他之前和我讲裸训一直爆炸。
#84
user1
我让他加载官网的swin权重进去试试。
#86
user1
他意思是加载了之后网络实际上还是有问题的呀?后面权重都是0的话。
#87
user2
说是到一半这样的。而且他加载的就是官网的那个模型。
#88
user1
那还行,按理说用swin应该比resnet50效果要好一点儿,让他坐后面说的实验吧,换优化器和学习策略。
#89
user2
老师他换优化器遇到点问题,我也不懂,让他找您了哈。
#91
user2
嗯嗯行。何老师 我们现在遇到一个问题:多卡跑的时候如果启动单卡任务,多卡就会断;如果单卡跑的时候启动多卡,单卡也会断。这种情况有时候发生有时候又不发生。
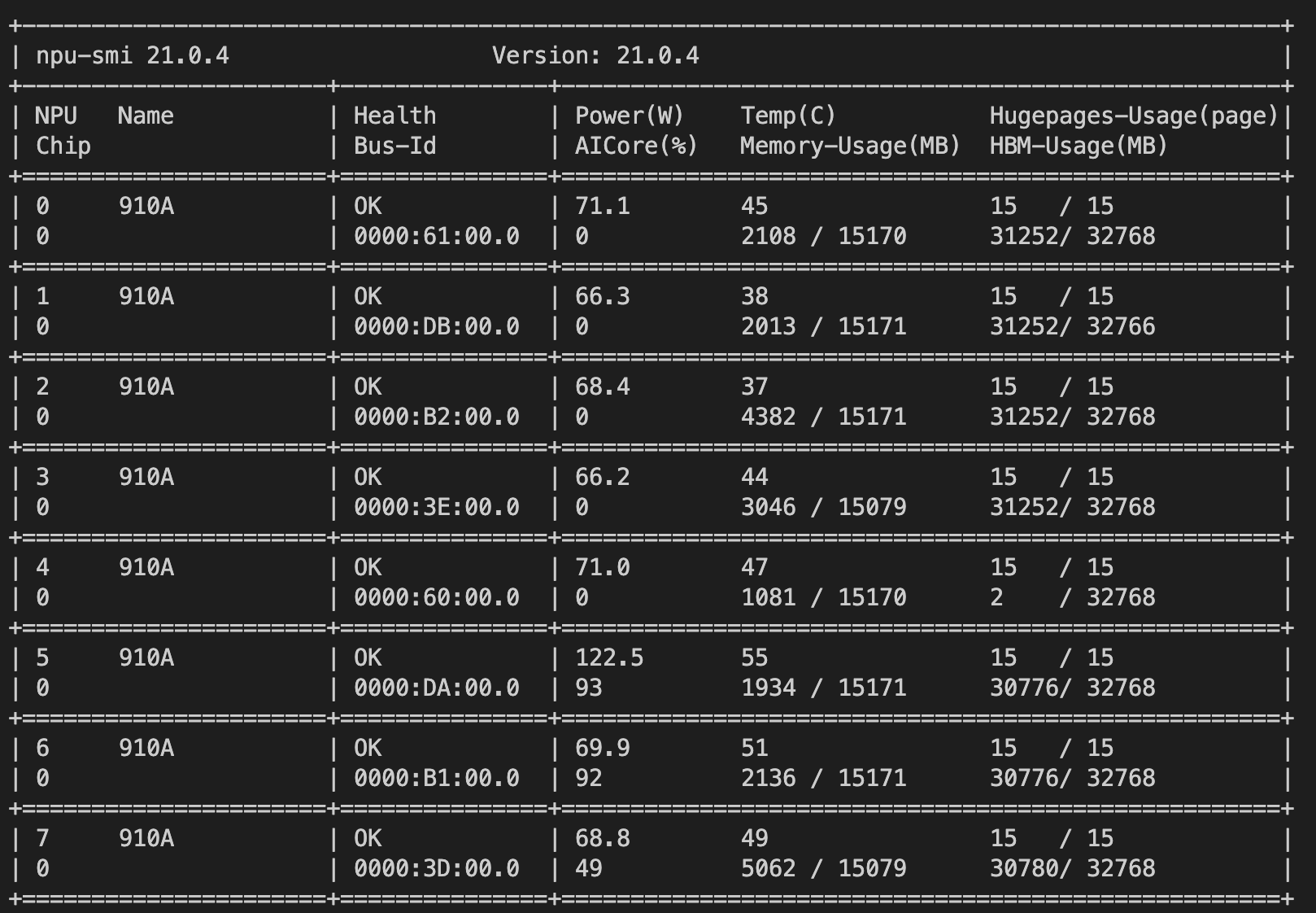
#94
user1
会不会是其他人kill的命令不对,误kill了进程啊。
#95
user2
就报这种错。我们正在聊天呢。没有人kill。
#96
user1
这种错误很难说,目前mindspore版本是多少呢?